ADVANCEMENTS IN VISION–LANGUAGE MODELS FOR REMOTE SENSING: DATASETS, CAPABILITIES, AND ENHANCEMENT TECHNIQUES
INDEX
Table of Contents
1. Discriminative Models (Traditional AI Approaches)
2. Vision–Language Models (VLMs: Generative AI)
3. Vision–Language Models (VLMs)
3. Automatically Annotated Datasets
2. Advanced Conversational VLMs
GAPS AND FUTURE WORK IN VISION–LANGUAGE MODELS (VLMS) FOR REMOTE SENSING
Identified Gaps (Current Shortcomings)
Resume
1. General Idea
- Main Focus/Research Question: The paper reviews advancements in Vision–Language Models (VLMs) for remote sensing, focusing on their capabilities, datasets, and enhancement techniques. It evaluates how VLMs address limitations of traditional discriminative models in tasks like geophysical classification, object detection, and scene understanding.
- Significance: VLMs bridge visual and linguistic data, enabling multi-task learning, human-like reasoning, and zero-/few-shot adaptability. This represents a transition from task-specific AI to flexible generative AI in remote sensing, with applications in disaster monitoring, urban planning, and environmental management.
- Contribution: Provides a structured review of VLM architectures, datasets, and enhancement strategies specific to remote sensing, highlighting their potential to generalize across tasks and integrate language-guided reasoning.
2. Methodology
- Methods: A systematic literature review using Google Scholar with keywords like “Visual language models for remote sensing.”
- Experimental Design:
- Dataset Categorization: Classifies datasets into manual (high-quality, task-specific), combined (merged existing datasets), and automatically annotated (generated via VLMs/LLMs like GPT-4).
- Model Analysis: Compares contrastive (e.g., CLIP-based) and conversational (e.g., LLaVA-based) VLM frameworks.
- Performance Evaluation: Benchmarks models on tasks (e.g., VQA, image captioning) using datasets like AID, NWPU-RESISC45, and LEVIR-CD.
- Tools/Algorithms: CLIP, ViT, LLaVA, Vicuna, GPT-4, and specialized models like RemoteCLIP and SkySenseGPT.
3. Gaps from Previous Work
- Limitations of Prior Methods: Traditional discriminative models (e.g., CNNs, U-Net) were single-task, lacked multimodal integration, and struggled with long-tail distributions or commonsense reasoning.
- Proposed Method Differences: VLMs unify tasks into generative frameworks, aligning language and vision for multi-task flexibility and human-like interaction. They incorporate pre-trained LLMs (e.g., Vicuna) and domain-specific adapters (e.g., Q-Formers) for improved generalization.
- Shortcomings Addressed: Overcomes rigid task boundaries, poor zero-shot adaptability, and limited scalability of earlier AI models.
4. Rationale for Proposed Method
- Method Choice: VLMs were selected for their ability to merge language and vision, enabling open-ended reasoning and multi-task learning. Pre-trained LLMs (e.g., LLaMA) reduce training costs, while alignment layers (MLPs, attention mechanisms) bridge modalities.
- Theoretical/Practical Justification: Aligns with the need for models that handle diverse remote sensing data (e.g., SAR, hyperspectral) and complex queries. Automatically annotated datasets (e.g., RS5M) scale training while minimizing manual effort.
- Alignment with Gaps: Addresses prior limitations by leveraging generative frameworks, cross-modal alignment, and large-scale pretraining.
5. Advantages of the Proposed Method
- Key Benefits:
- Multi-task Flexibility: Handles classification, captioning, VQA, and grounding in a single framework.
- Generalization: Pre-training on diverse datasets (e.g., RS5M) improves zero-shot performance.
- Performance Metrics: Conversational VLMs (e.g., SkySenseGPT) achieve 95.1% accuracy on AID for scene classification and outperform contrastive models in VQA (e.g., 79.6% on RSVQA-HR).
- Impact: Enables region-specific dialogue (GeoChat), time-series analysis (Changen2), and high-precision captioning (RSICap).
6. Future Work
- Author Suggestions:
- Regression Tasks: Improve numerical tokenization and integrate regression heads (e.g., REO-VLM’s MLP-mixer).
- Multispectral/SAR Adaptation: Develop domain-specific feature extractors and pseudo-RGB strategies for non-RGB data.
- Multimodal Outputs: Enable image/video generation (e.g., Emu3’s next-token prediction) and agent-based activation of specialized models.
- Temporal Analysis: Incorporate multitemporal data for trend inference (e.g., climate change monitoring).
- Unresolved Challenges: Domain-specific benchmarks, efficient training for large models, and handling rare/ambiguous annotations.
Conclusion
- Contributions: This review systematizes VLM advancements in remote sensing, highlighting their transition from discriminative to generative AI. It catalogs datasets (e.g., RS5M, RSICap), model architectures (e.g., contrastive vs. conversational), and enhancement techniques (e.g., alignment layers).
- Impact: VLMs enable scalable, flexible solutions for geospatial analysis, with implications for disaster response, urban planning, and environmental monitoring. Future progress hinges on addressing domain-specific data challenges and expanding into temporal/multimodal reasoning.
- Implications: Establishes VLMs as foundational tools for next-gen remote sensing AI, bridging vision, language, and domain expertise.
Note in detail:
INTRODUCTION
1. Discriminative Models (Traditional AI Approaches)
(A) Convolutional Neural Networks (CNNs)
- 3D CNNs
- Purpose: Designed for hyperspectral and multispectral image classification and spectral reconstruction.
- Pros:
- Captures spatial-spectral features simultaneously.
- Effective for volumetric data (e.g., hyperspectral cubes).
- Cons:
- Computationally expensive due to 3D convolutions.
- Limited scalability to very high-resolution imagery.
- U-Net
- Purpose: Semantic segmentation and land cover mapping in aerial imagery.
- Pros:
- Skip connections preserve spatial details.
- Works well with limited labeled data.
- Cons:
- Struggles with fine-grained object boundaries in very high-resolution images.
- Requires extensive training for domain adaptation.
- Pyramid Networks for SAR Images
- Purpose: Multi-scale object detection in Synthetic Aperture Radar (SAR) imagery.
- Pros:
- Handles scale variation in SAR targets (e.g., ships, buildings).
- Robust to speckle noise.
- Cons:
- Complex architecture with high memory usage.
- Limited adaptability to rare object classes.
- YOLO Framework
- Purpose: Small target detection in infrared remote sensing.
- Pros:
- Real-time inference.
- Efficient for detecting small objects (e.g., vehicles, aircraft).
- Cons:
- Struggles with densely clustered targets.
- Lower precision in low-contrast scenarios (e.g., foggy or cloudy conditions).
- FFCA-YOLO
- Purpose: Enhances small object detection with plug-and-play modules for feature fusion and context awareness.
- Pros:
- Boosts local/global feature correlation without increasing complexity.
- Maintains computational efficiency.
- Cons:
- Still inherits YOLO’s limitations in complex backgrounds.
- Improved YOLOv5 (Zhang et al.)
- Purpose: Enhanced object detection via spatial-to-depth (SPD) and CoTC3 modules.
- Pros:
- Improves contextual information utilization.
- Better performance on multi-scale targets.
- Cons:
- Increased parameter count may reduce efficiency.
- MLPA (Multi-Level Feature Alignment)
- Purpose: Cross-domain hyperspectral image (HSI) classification.
- Pros:
- Aligns features across domains (e.g., satellite to UAV).
- Improves generalization to unseen environments.
- Cons:
- Requires paired data for alignment.
- Computational overhead during training.
- LBA-MCNet
- Purpose: Object Saliency Detection (ORSI-SOD) with boundary refinement.
- Pros:
- Balances foreground/background context modeling.
- Effective for ambiguous object edges.
- Cons:
- Sensitive to initial segmentation quality.
- MSC-GAN
- Purpose: Multitemporal cloud removal via generative adversarial networks (GANs).
- Pros:
- Reconstructs cloud-free images using temporal data.
- Efficient feature interaction reduces artifacts.
- Cons:
- Struggles with thick cloud coverage.
- Requires aligned multitemporal inputs.
2. Vision–Language Models (VLMs: Generative AI)
- CLIP
- Purpose: Aligns images and text for cross-modal tasks (e.g., zero-shot classification).
- Pros:
- Generalizes across datasets without fine-tuning.
- Multimodal understanding improves interpretability.
- Cons:
- Limited spatial resolution awareness.
- Text prompts must be carefully designed for remote sensing.
- LLaVA/GPT-4
- Purpose: Combines visual encoders (e.g., ViT) with large language models (LLMs) for open-ended vision-language tasks.
- Pros:
- Supports multi-task workflows (e.g., VQA, captioning).
- Human-like reasoning for geospatial analysis.
- Cons:
- Computationally intensive (requires GPUs).
- Fine-tuning needed for domain-specific terms (e.g., SAR).
- GeoChat
- Purpose: Regional dialogue and geographic queries (e.g., administrative boundaries).
- Pros:
- Accepts region-based inputs for localized analysis.
- Integrates geospatial knowledge (e.g., OpenStreetMap).
- Cons:
- Early-stage tool with limited real-world adoption.
- RSICap
- Purpose: Remote sensing image captioning via high-quality annotated datasets.
- Pros:
- Enables human-readable descriptions for RS imagery.
- Supports model fine-tuning for domain adaptation.
- Cons:
- Manual annotation is labor-intensive.
- Changen2
- Purpose: Generates time-series imagery with change labels for multitemporal analysis.
- Pros:
- Reduces annotation costs via synthetic data.
- Useful for disaster monitoring (e.g., deforestation).
- Cons:
- Synthetic data may lack real-world complexity.
Comparison: Discriminative vs. Generative Models
|
ASPECT |
DISCRIMINATIVE MODELS |
VISION–LANGUAGE MODELS (VLMS) |
|
Task Flexibility |
Single-task (e.g., classification, detection). |
Multi-task (e.g., VQA, captioning, retrieval). |
|
Data Requirements |
Label-intensive for specific tasks. |
Leverages unlabeled data via pre-training. |
|
Adaptability |
Limited to trained domains. |
Zero/few-shot learning; better generalization. |
|
Interpretability |
Low (black-box predictions). |
High (human-like explanations via text). |
|
Computation |
Efficient for edge deployment. |
Requires heavy computational resources. |
Conclusion
- Discriminative Models excel in fast, task-specific applications (e.g., object detection) but lack flexibility and require extensive labeled data.
- Vision–Language Models address multi-task challenges and enable human-AI collaboration but face computational and domain-adaptation hurdles. Future work in remote sensing VLMs should focus on efficiency (e.g., lightweight LLMs), domain-specific pretraining (e.g., SAR/HSI alignment), and multimodal output (e.g., maps, 3D models).
![]()
![]()
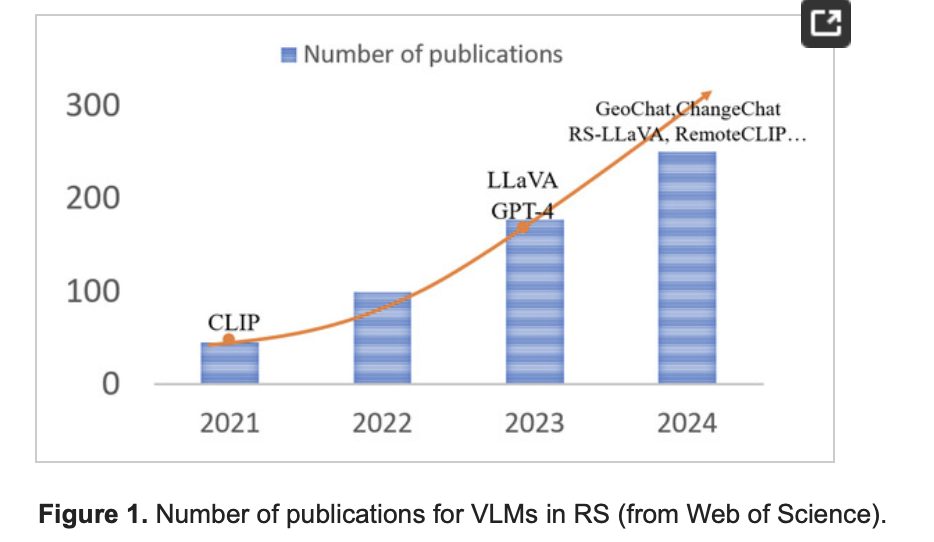
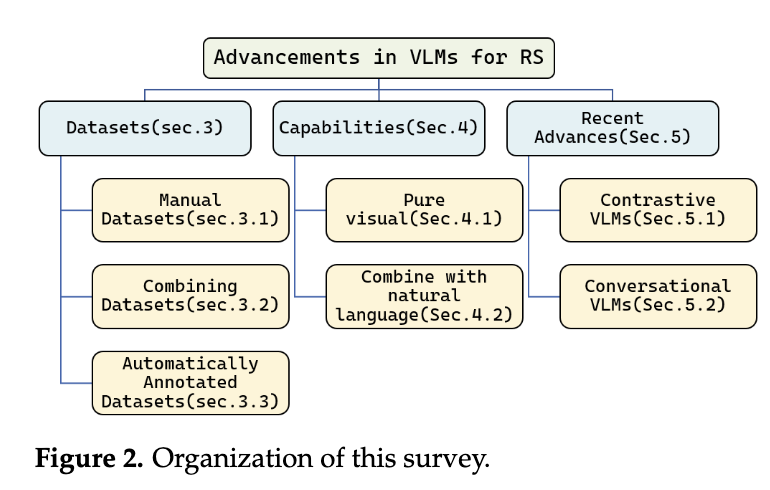
Foundation Models
1. Transformer
Overview:
The Transformer is a neural network architecture introduced in 2017 for
natural language processing (NLP). It replaces traditional sequential models
(e.g., RNNs, LSTMs) with a parallelizable self-attention mechanism.
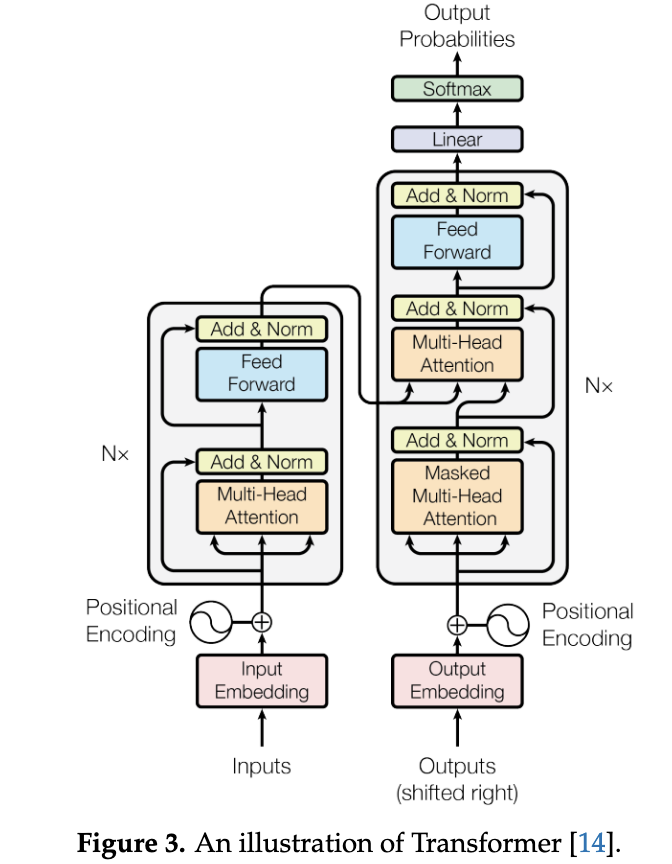
Key Components:
- Encoder-Decoder Structure:
- Encoder: Processes input tokens via self-attention and feed-forward layers.
- Decoder: Generates output tokens using masked self-attention (to prevent future token leakage) and cross-attention (to focus on encoder outputs).
- Attention Mechanism:
- Self-Attention: Computes relationships between all input tokens simultaneously using Query (Q), Key (K), and Value (V) matrices.
- Formula:
Attention(Q,K,V)=Softmax(dkQKT)V - Scaling Factor (dk): Normalizes dot products to stabilize gradients.
- Cross-Attention: Uses Q from one sequence (e.g., decoder) and K, V from another (e.g., encoder).
- Feed-Forward Network (FFN):
- Two linear layers with ReLU activation, expanding dimensions (e.g., 4× input width), and contracting back.
Advantages:
- Parallel Processing: Unlike RNNs, processes all tokens simultaneously, speeding up training.
- Long-Range Dependencies: Captures relationships between distant tokens (e.g., sentence context).
- Scalability: Foundation for large language models (LLMs) like GPT and BERT.
2. Vision Transformer (ViT)
Adaptation for
Images:
ViT applies Transformer architecture to image processing by treating images as
sequences of patches.
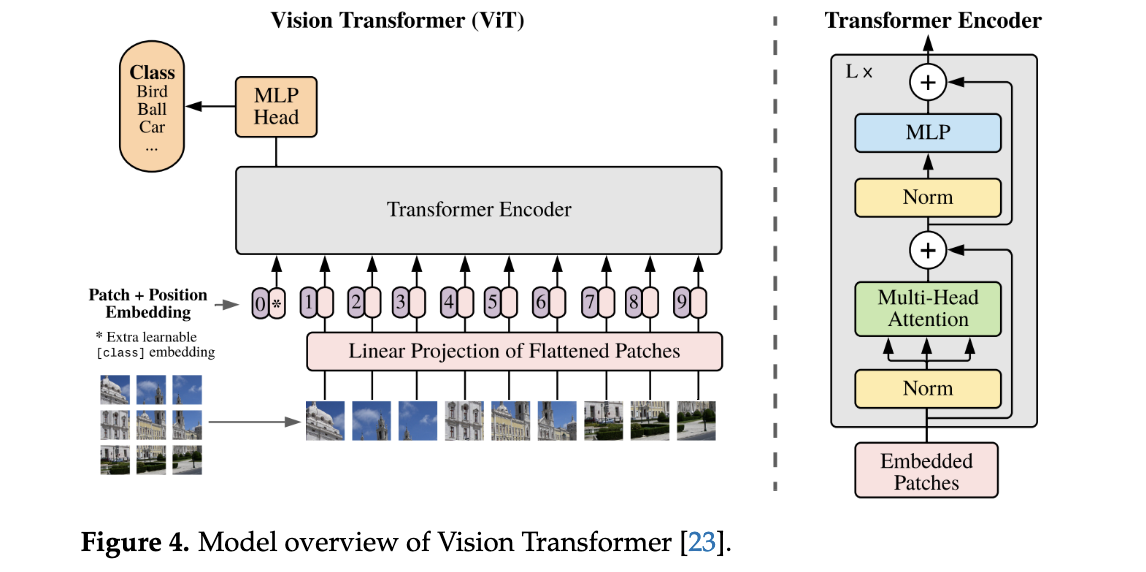
Key Steps:
- Patch Embedding:
- Splits an image into fixed-size patches (e.g., 16×16 pixels).
- Flattens patches into vectors and projects them into embeddings using a linear layer.
- Position Embeddings:
- Adds learnable positional encodings to retain spatial information.
- Types: Absolute (fixed positions), Relative (distance-based), Rotary (rotation-sensitive).
- Transformer Encoder:
- Processes patch embeddings through self-attention and FFN layers.
- Classification Head (MLP):
- Aggregates global features for tasks like image classification.
Advantages Over CNNs:
- Scalability: Performance improves with larger models/data (no saturation).
- Global Context: Self-attention captures relationships across the entire image.
Variants:
- SwinTransformer: Hierarchical attention with shifted windows for efficiency.
- DeiT: Distillation-based training for data-efficient ViTs.
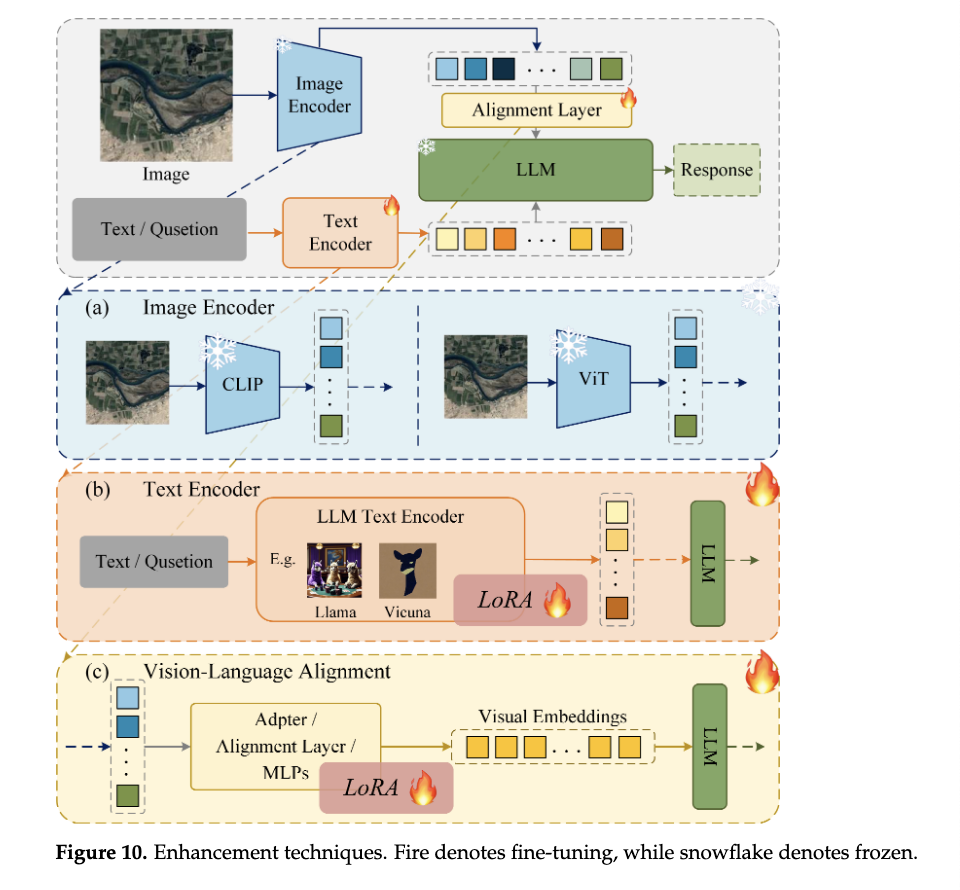
3. Vision–Language Models (VLMs)
Unifying Vision
and Language:
VLMs integrate visual (ViT) and textual (LLM) processing for multimodal tasks
(e.g., captioning, VQA).
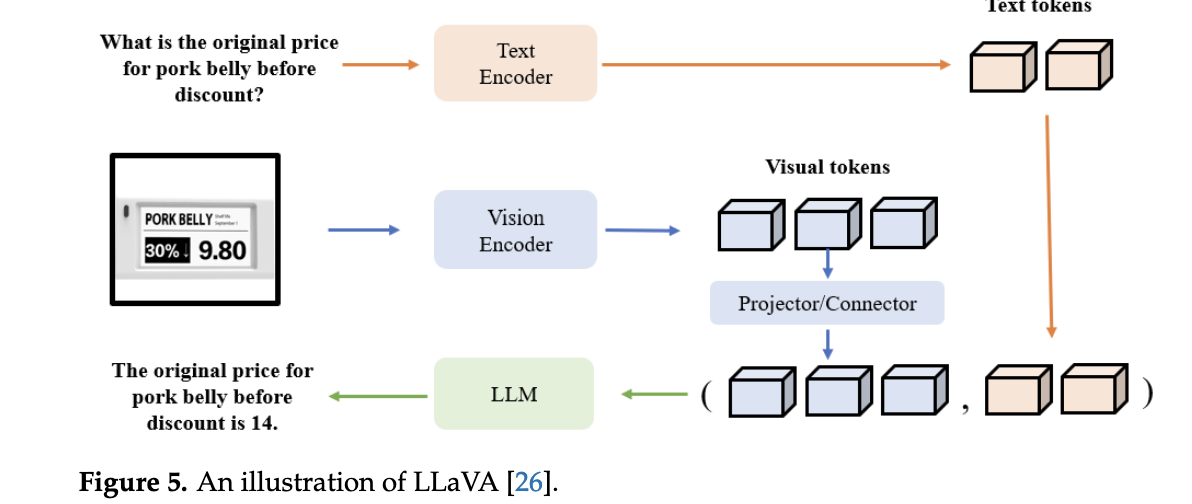

Example Architecture (LLaVA):
- Visual Encoder:
- Uses CLIP-ViT to extract image features, pre-trained on image-text pairs for alignment.
- Projection Layer:
- Maps visual features to language-embedding space (e.g., via linear layers).
- Large Language Model (LLM):
- Processes combined visual and text tokens (e.g., Vicuna, LLaMA).
- Generates text outputs (e.g., answers, descriptions) based on multimodal input.
Key Strengths:
- Multitasking: Handles diverse tasks (classification, captioning, reasoning) in one framework.
- Zero/Few-Shot Learning: Leverages pre-trained knowledge for unseen tasks (e.g., GPT-4).
- Human Interaction: Enables conversational interfaces (e.g., region-specific queries in GeoChat).
Example Applications:
- GeoChat: Combines ViT with LLM for geospatial analysis (e.g., boundary mapping).
- CLIP: Aligns image-text pairs for zero-shot classification.
Summary
- Transformer: Revolutionized NLP with parallelizable self-attention.
- ViT: Adapted Transformers for vision via patch embeddings, outperforming CNNs at scale.
- VLMs:
Bridge vision-language modalities (e.g., LLaVA) for flexible, human-like
AI tasks.
Impact: Foundation for generative AI (e.g., ChatGPT, DALL-E) and domain-specific tools (e.g., remote sensing VLMs).
DATASET
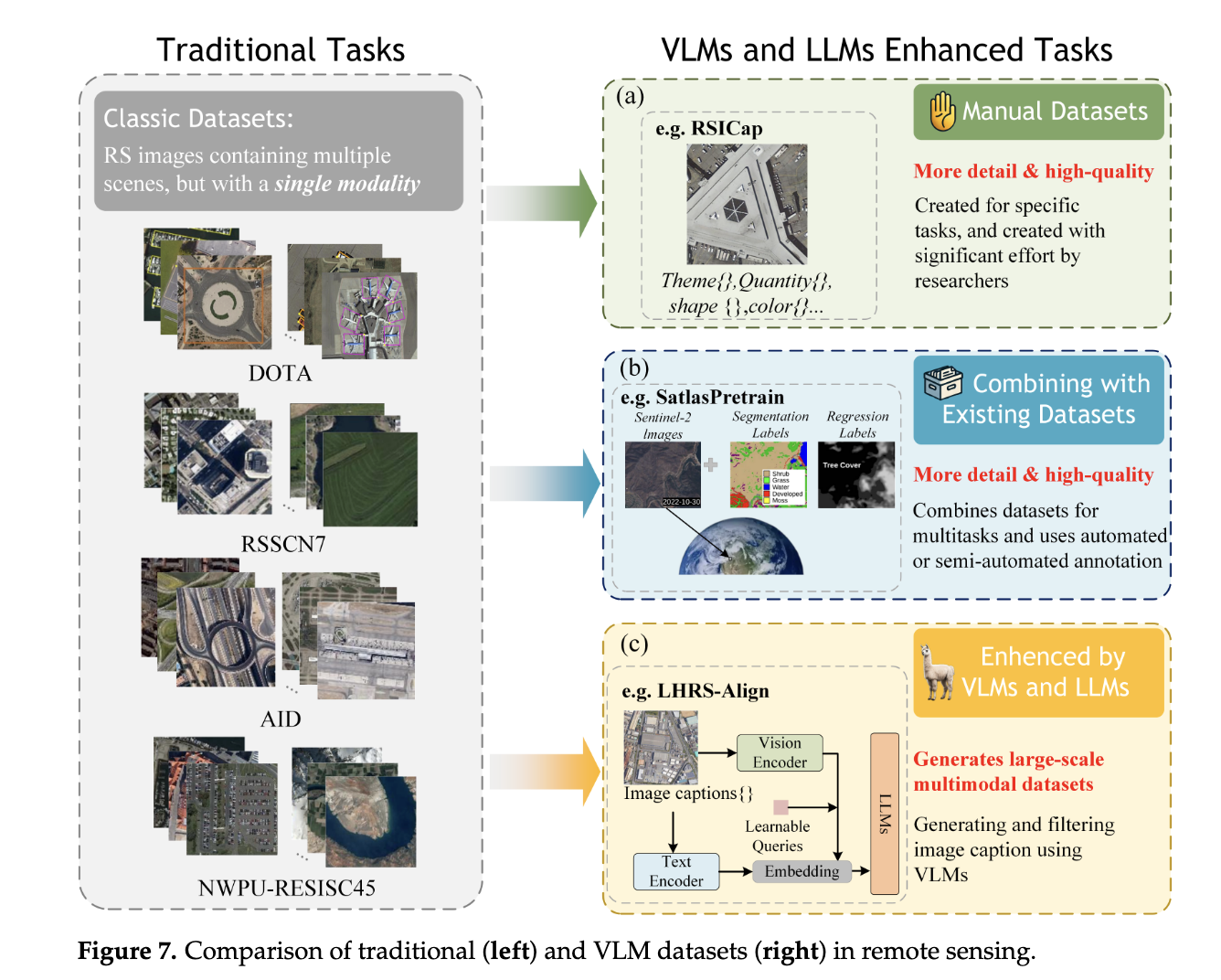
1. Manual Datasets
- Description: Expert-curated, small-scale datasets with high-quality annotations.
- Examples:
- HallusionBench: Tests VLM robustness via 455 visual-QA pairs (346 images, 1129 questions).
- RSICap’s RSIEval: Provides five expert captions per image for fine-tuning.
- CRSVQA: Uses domain experts to craft complex questions, reducing language bias.
- Pros:
- High accuracy and task alignment.
- Minimizes redundancy and bias.
- Cons:
- Time-consuming, expensive, and small scale.
- Limited generalization due to size.
- Use Case: Fine-tuning VLM models for specific tasks.
2. Combined Datasets
- Description: Merges existing RS datasets (e.g., Sentinel-2, AID, DIOR) to create large-scale resources.
- Examples:
- AID/NWPU-RESISC45: Scene classification.
- FAIR1M/DIOR: Object detection.
- LEVIR-CD: Change detection.
- Million-AID: Benchmark dataset.
- Pros:
- Cost-effective and scalable (millions of entries).
- Facilitates multi-task learning.
- Cons:
- Requires preprocessing (format/resolution alignment).
- Lower annotation quality compared to manual datasets.
- Use Case: Pre-training VLMs on diverse RS tasks.
3. Automatically Annotated Datasets
- Description: Leverages LLMs/VLMs (e.g., BLIP2, GPT-4, CLIP) to generate image-text pairs at scale.
- Examples:
- RS5M: Auto-generates captions using BLIP2 and CLIP filtering.
- SkyScript: Matches OSM attributes with Google Images.
- GeoChat/GPT-4: Creates dialogue datasets via prompts.
- HqDC-1.4M: Uses Gemini for multi-dataset captioning.
- Pros:
- Massive scale with flexible annotations (captions, Q&A pairs).
- Cost-efficient and adaptable to new tasks.
- Cons:
- Risk of model-induced errors/bias.
- Requires hybrid human-AI validation.
- Use Case: Mainstream pre-training and task-specific adaptation (e.g., disaster monitoring).
Comparison
|
TYPE |
SCALE |
QUALITY |
COST |
BEST FOR |
|
Manual |
Small |
High (expert) |
High |
Task-specific fine-tuning. |
|
Combined |
Large |
Moderate |
Low |
Pre-training, multi-task. |
|
Auto-Annotated |
Massive |
Moderate-High |
Low |
Scalable pre-training, diverse tasks. |
Key Takeaways
- Manual Datasets: Critical for niche tasks requiring precision but impractical for large models.
- Combined Datasets: Balance scale and diversity but need heavy preprocessing.
- Auto-Annotated Datasets: Dominant due to scalability and LLM efficiency, though quality control via hybrid validation is essential.
- Trend: Auto-annotated datasets are becoming the cornerstone of VLM development in RS, supplemented by manual data for refinement.
Capabilities

1. Pure Visual Tasks
Tasks that analyze remote sensing imagery without textual input to extract geospatial insights.
|
TASK |
PURPOSE |
KEY DATASETS |
DATASET FEATURES |
APPLICATIONS |
|
Scene Classification (SC) |
Classify images into land-use/land-cover categories. |
AID, NWPU-RESISC45, UCM |
AID: 10k images, 30 classes; NWPU-RESISC45: 31.5k images, 45 classes; UCM: 2.1k images, 21 classes. |
Urban planning, environmental monitoring. |
|
Object Detection (OD) |
Detect and localize objects (e.g., buildings, vehicles). |
DOTA, DIOR |
DOTA: 2,806 aerial images, 15 classes; DIOR: 23,463 images, 20 classes, 192k+ instances. |
Traffic monitoring, military reconnaissance. |
|
Semantic Segmentation (SS) |
Assign pixel-level labels to objects in images. |
ISPRS Vaihingen, iSAID |
ISPRS: High-res (5 cm) TOP images; iSAID: 2,806 aerial images from Google Earth. |
Disaster assessment, crop yield estimation. |
|
Change Detection (CD) |
Identify changes (e.g., urban expansion, deforestation) in multitemporal images. |
LEVIR-CD, AICD, Google Data Set |
LEVIR-CD: Building-focused changes; AICD: Synthetic dataset for algorithm testing. |
Environmental monitoring, damage assessment. |
|
Object Counting (OC) |
Estimate the number of objects (e.g., vehicles, trees) in images. |
RemoteCount (based on DOTA validation set) |
Derived from DOTA dataset; manually annotated for counting. |
Urban planning, wildlife conservation. |
Key Strengths of VLMs:
- Enable zero-shot/few-shot learning (e.g., classify unseen land-cover types).
- Handle rare objects via pretraining on large-scale datasets like DIOR.
2. Vision–Language Tasks
Tasks that combine imagery with natural language for multimodal reasoning.
|
TASK |
PURPOSE |
KEY DATASETS |
DATASET FEATURES |
APPLICATIONS |
|
Image Retrieval (IR) |
Retrieve relevant images from massive repositories using textual queries. |
Custom large-scale repositories |
Built from satellite data (e.g., Sentinel-2, Gaofen) for multimodal search. |
Disaster response, historical analysis. |
|
Visual Question Answering (VQA) |
Answer open-ended questions about RS imagery (e.g., "Is there flooding?"). |
RSVQA-LR, RSVQA-HR |
RSVQA-LR: Low-res; RSVQA-HR: High-res; both include diverse Q&A pairs. |
Real-time monitoring, educational tools. |
|
Image Captioning (IC) |
Generate descriptive text summaries of RS imagery. |
RSICD, NWPU-Captions, CapERA |
RSICD: 10k+ images with 5 captions each; CapERA: UAV videos with text descriptions. |
Automated reporting, accessibility tools. |
|
Visual Grounding (VG) |
Localize objects described in text (e.g., "Find the red-roofed building"). |
RSVGD (DIOR-based) |
192k+ instances with text queries; addresses scale/clutter challenges. |
Military targeting, infrastructure inspection. |
|
Remote Sensing Image Change Captioning (RSICC) |
Describe land-cover changes in multitemporal images. |
LEVIR-CC |
10k image pairs with 50k sentences detailing changes. |
Climate change analysis, post-disaster assessment. |
|
Referring to Remote Sensing Image Segmentation (RRSIS) |
Segment objects based on textual prompts (e.g., "Mask flooded areas"). |
RefSegRS, RRSIS-D |
RefSegRS: pixel-level masks; RRSIS-D: 17k+ image-caption-mask triplets. |
Precision agriculture, hazard mapping. |
Key Strengths of VLMs:
- Multimodal Flexibility: Perform tasks like captioning, VQA, and segmentation in a unified framework.
- Human-Like Reasoning: Answer complex queries (e.g., "Count vehicles near the highway exit").
- Generalization: Adapt to novel tasks (e.g., RSICC) with minimal fine-tuning.
Comparison of Pure Visual vs. Vision–Language Tasks
|
ASPECT |
PURE VISUAL TASKS |
VISION–LANGUAGE TASKS |
|
Input |
Images only. |
Images + Text (queries/captions). |
|
Focus |
Feature extraction (spatial/spectral patterns). |
Multimodal interaction (language-guided analysis). |
|
Complexity |
Narrowly scoped (single-task models). |
Broadly scoped (multi-task, open-ended). |
|
Dataset Requirements |
Large labeled image datasets. |
Image-text pairs or annotated Q&A datasets. |
|
Example Use Case |
Classify urban vs. rural areas. |
Answer: "How many buildings were constructed after 2020 in this region?" |
Impact of VLMs in Remote Sensing
- Advantages Over Traditional Models:
- Multitasking: Replace siloed models with unified frameworks (e.g., LLaVA handles OD, IC, and VQA).
- Scalability: Leverage pretrained LLMs (e.g., GPT-4, Vicuna) for zero-shot adaptation.
- Interpretability: Generate human-readable explanations (e.g., change descriptions in RSICC).
- Challenges:
- Data Bias: Auto-annotated datasets may inherit biases from LLMs.
- Computational Cost: Training VLMs requires significant GPU resources.
RECENT ADVANCES
1. Contrastive VLMs
Objective: Align image and text features in a shared embedding space.
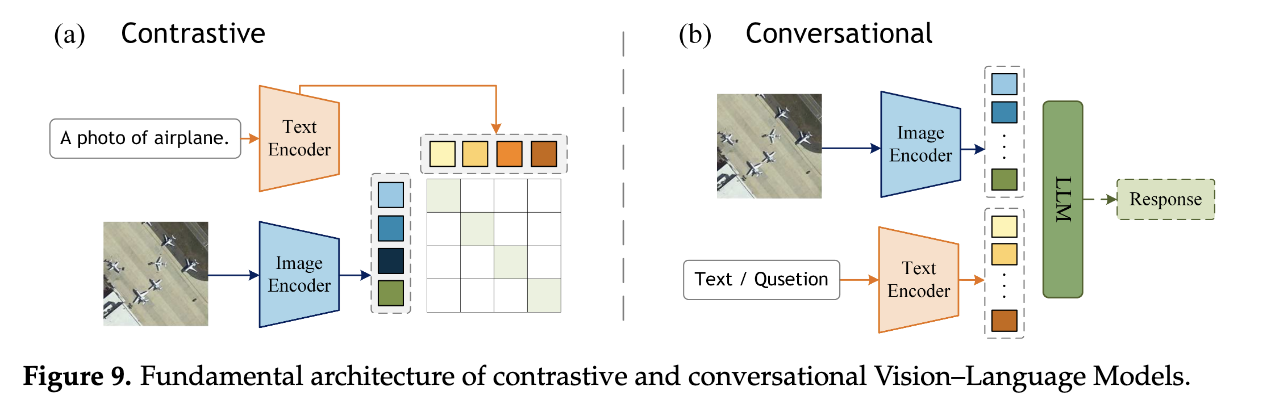
Key Models:
- RemoteCLIP: Combines existing datasets and fine-tunes CLIP for remote sensing, enabling multi-task capabilities (zero-shot classification, retrieval).
- GeoRSCLIP: Uses 5M image-text pairs with CLIP fine-tuning for geospatial generalization.
- ChangeCLIP: Uses a Differentiable Feature Calculation (DFC) layer for change detection tasks.
Methods:
- Training: Contrastive loss (InfoNCE) to maximize similarity between matched image-text pairs.
- Data: Combines existing datasets (e.g., AID, DIOR) or auto-annotated data for scalability.
Pros:
- Efficient pre-training for downstream tasks.
- Strong generalization to unseen classes (zero/few-shot).
Cons:
- Limited to simple alignment tasks (no complex reasoning).
- Requires domain adaptation for geospatial nuances.
2. Advanced Conversational VLMs
Objective: Integrate LLMs (e.g., Vicuna, LLaMA) with vision encoders for multimodal reasoning.
Key Models:
- SkyEyeGPT: Uses a CLIP-based encoder and Vicuna LLM, excelling in VQA and captioning.
- RS-LLaVA: Combines LLaVA with domain-specific image encoders for geospatial semantics.
- EarthGPT: Integrates SAR/infrared imagery with ViT for multimodal analysis.
Methods:
- Image Encoders: CLIP variants, EVA-CLIP, or hybrid ViT-CNN architectures.
- Alignment: MLP projection layers or learnable query embeddings (e.g., Q-Former).
- Training: Instruction tuning on remote sensing-specific datasets (e.g., RRSIS-D).
Pros:
- Handle complex tasks (VQA, change captioning, segmentation).
- Support region-specific queries and human-like reasoning.
Cons:
- High computational demands (large LLMs).
- Requires extensive fine-tuning for domain alignment.
3. Specialized Models
Objective: Address
domain-specific challenges beyond general-purpose VLMs.
Key Models:
- SpectralGPT: Trained on spectral data (1M images) for classification and change detection.
- CPSeg: Uses language prompts for flood segmentation.
- GeoCLIP: Aligns satellite images with GPS coordinates for geo-localization.
- TEMO: Enhances few-shot object detection via text-visual fusion.
Methods:
- Adaptations: Spatial-spectral tokenization (SpectralGPT), hash-based retrieval (SHRNet).
- Data: Leverages specialized datasets (e.g., DIOR for few-shot detection).
Pros:
- Optimized for niche tasks (e.g., spectral analysis, geo-localization).
- Efficient in resource-constrained scenarios (e.g., TEMO for few-shot learning).
Cons:
- Lack generalizability to broader tasks.
- Dependent on large annotated datasets (e.g., EuroSAT for SpectralGPT).
Performance Comparison
|
MODEL TYPE |
BEST PERFORMANCE |
STRENGTHS |
WEAKNESSES |
|
Contrastive VLMs |
95.1% SC (AID), 89.3% IR (WHU-RS19) |
Zero-shot adaptability, efficient pre-training. |
Limited to retrieval/classification. |
|
Conversational VLMs |
79.6% VQA (RSVQA-HR), 98.2% IC (EuroSAT) |
Multi-task flexibility, human-like reasoning. |
High computational cost, complex fine-tuning. |
|
Specialized Models |
99.21% SC (SpectralGPT), 75.1% OD (TEMO) |
Domain-specific accuracy (e.g., floods, spectra). |
Narrow applicability, data dependency. |
Key Findings:
- Conversational VLMs surpass contrastive models in tasks requiring reasoning (e.g., VQA, IC).
- Contrastive VLMs excel in data efficiency but lack nuanced interaction.
- Specialized models are critical for niche applications but do not generalize.
Conclusion
- Contrastive VLMs: Ideal for tasks needing robust feature alignment (e.g., retrieval).
- Conversational VLMs: Preferred for complex, open-ended tasks (e.g., multisensor analysis) despite higher resource demands.
- Specialized
Models: Fill gaps in spectral, geo-localization, and few-shot tasks.
Future Direction: Unified benchmarks and hybrid approaches (e.g., conversational + spectral models) will drive next-gen VLMs in remote sensing.
GAPS AND FUTURE WORK IN VISION–LANGUAGE MODELS (VLMS) FOR REMOTE SENSING
Identified Gaps (Current Shortcomings)
- Regression Tasks:
- Issue: Tokenization of numerical values (e.g., "100" split into "1" and "00") leads to precision loss in regression tasks like Above-Ground Biomass (AGB) estimation.
- Root Cause: Text-based tokenizers fail to capture numerical relationships, limiting VLMs in tasks requiring continuous value predictions.
- Structural Characteristics of Remote Sensing (RS) Data:
- Issue: Existing VLMs rely on RGB-specific architectures and lack specialized models for multispectral (e.g., HSI) or radar (e.g., SAR) data.
- Root Cause: Pre-training frameworks are inherited from general computer vision, compromising performance on SAR/HSI modalities.
- Multimodal Output Limitation:
- Issue: VLMs produce text-only outputs, limiting their utility in dense prediction tasks (e.g., segmentation, 3D modeling).
- Root Cause: Current architectures prioritize language generation over joint text-visual outputs (e.g., images or masks).
- Temporal Data Handling:
- Issue: VLMs focus on static imagery, neglecting temporal dynamics critical for climate monitoring and land-use prediction.
- Root Cause: Lack of sequence modeling frameworks to encode multitemporal remote sensing data.
Future Work Directions
- Enhancing Regression Capabilities:
- Specialized Tokenizers: Design tokenizers to preserve numerical precision (e.g., treating "100" as a single token).
- Regression Heads: Integrate task-specific heads (e.g., MLP-mixers) to bypass text token limitations.
- Mixture of Experts (MOE): Use gating mechanisms to dynamically activate regression modules for multi-task learning.
- Example: REO-VLM employs hybrid visual-language embeddings for accurate AGB estimation.
- Domain-Specific Architectures for RS Data:
- Multispectral/SAR Encoders: Develop feature extractors tailored to hyperspectral or radar data (e.g., pseudo-RGB conversion for SAR).
- Multimodal Datasets: Expand datasets to include SAR, HSI, LiDAR, and text pairs for robust cross-modal alignment.
- Multimodal Output Generation:
- Beyond Text: Enable VLMs to output images, videos, or 3D models (e.g., Emu3 uses next-token prediction for image generation).
- Hybrid Models: Integrate VLMs with task-specific heads (e.g., segmentation masks) using LLMs as "controllers."
- Temporal-Spatial Modeling:
- Sequence Encoding: Treat time-series RS data as sequential inputs for transformers to capture trends (e.g., deforestation).
- Predictive Analytics: Train VLMs on historical data to forecast environmental changes or disaster impacts.
Additional Considerations
- Benchmarking: Establish unified evaluation standards for cross-modal tasks (e.g., VQA, change captioning).
- Sustainability: Optimize energy-efficient training methods for large-scale VLMs to reduce computational costs.
- Ethical AI: Address biases in auto-annotated datasets to ensure fairness in applications like urban planning.
Conclusion
While VLMs have transformed remote sensing analysis, addressing gaps in regression, multimodality, domain adaptation, and temporal modeling will unlock their full potential. Future efforts should prioritize specialized architectures, temporal-spatial integration, and ethical, scalable solutions to bridge the gap between AI innovation and real-world geospatial challenges.